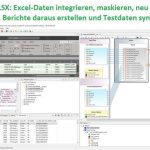
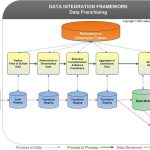
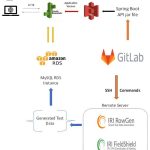
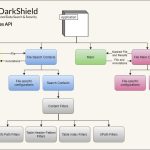
❌ Datenintegration und Datenmanagement ❌ DBTA listet wichtigste Funktionen für Data Management und sicherer Datenmaskierung für moderne Unternehmen ❗
Datenintegration und Datamanagement für moderne Unternehmen: Erkenntnisse und Ratschläge! In der DBTA-Ausgabe 2018 zum Thema Datenintegration und -governance haben wir einen MDM-bezogenen Anwendungsfall in Malaysia (das MyGDX-Portal) vorgestellt, bei dem die Datentransformations- und Datenqualitätsfunktionen des CoSort "SortCL"-Programms genutzt werden, das Weiterlesen