❌ Informationssicherheit ❌ Vormaskierung von Daten um Datenverstoß abzuschwächen oder komplett zunichte zu machen ❗
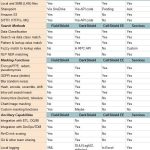
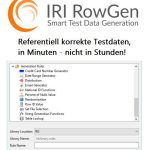
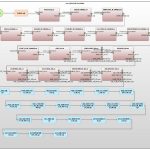
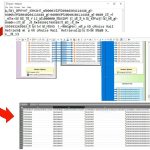
Preisgekrönte datenzentrische Sicherheit: Renommierte Softwareprodukte der IRI Datenschutz Suite oder der IRI Voracity Datenmanagement-Plattform werden personenbezogene Daten (PII) und andere "gefährdete Daten" in mehreren Quellen finden, klassifizieren und schützen. Jedes einzelne hilft Ihnen, die CCPA, CIPSEA, FERPA, HIPAA/HITECH, PCI DSS Weiterlesen