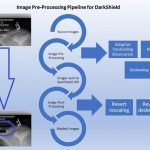
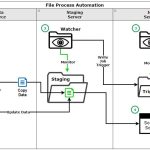
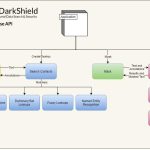
❌ PII in Cloud-Datenbank finden/schützen ❌ Automatische Datenmaskierung in Google Bigtable, Azure Cosmos DB und Amazon DynamoDB ❗
PII in Google BigTable, Azure Cosmos DB und Amazon DynamoDB finden und maskieren! Dieser Artikel behandelt die Verwendung der IRI DarkShield API zum automatischen Auffinden und De-Identifizieren von PII oder anderen sensiblen Daten in den drei großen NoSQL-Datenbanken der Cloud-Anbieter Weiterlesen