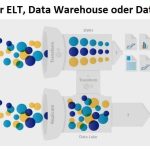
❌ Data Vault 2.0 ❌ Datenmigration von RDB-Datenbankmodell in eine Data Vault 2.0 Architektur – der hybride Ansatz ❗
End-to-End Datenmanagement: Die IRI Workbench IDE enthält einen Data Vault Generator Assistenten, der den Benutzern der IRI Voracity Plattform hilft, ein relationales Datenbankmodell in eine Data Vault 2.0 (DV) Architektur zu migrieren. Der Assistent hat drei Ausgabeoptionen, die von den Weiterlesen