
Den See säubern: Ein Hauptproblem bei Datenseen ist, wie bei echten Seen, dass die Menschen nicht wissen, was sich in ihnen befindet oder wie sauber sie sind. In der Natur können unbekannte Dinge im Wasser das Ökosystem zerstören. Unbekannte Daten in einem Datensee können das Projekt zerstören.
Dan Linstedt rät dazu: Wenn es keine Struktur gibt, gibt es kein Verständnis und es gibt keine Vision, wie diese Daten verwendet werden können oder wie man überhaupt versteht, was man hat. Die Daten müssen klassifiziert und bereinigt werden, um sie in wertschöpfende Informationen für das Unternehmen umzuwandeln. Um mit diesen Daten irgendeine Art von Geschäftsinformationen nutzen zu können, müssen Sie damit beginnen, sie zu schichten, zu profilieren, zu verwalten und zu verstehen, damit Sie aus ihnen Ergebnisse erzielen können.
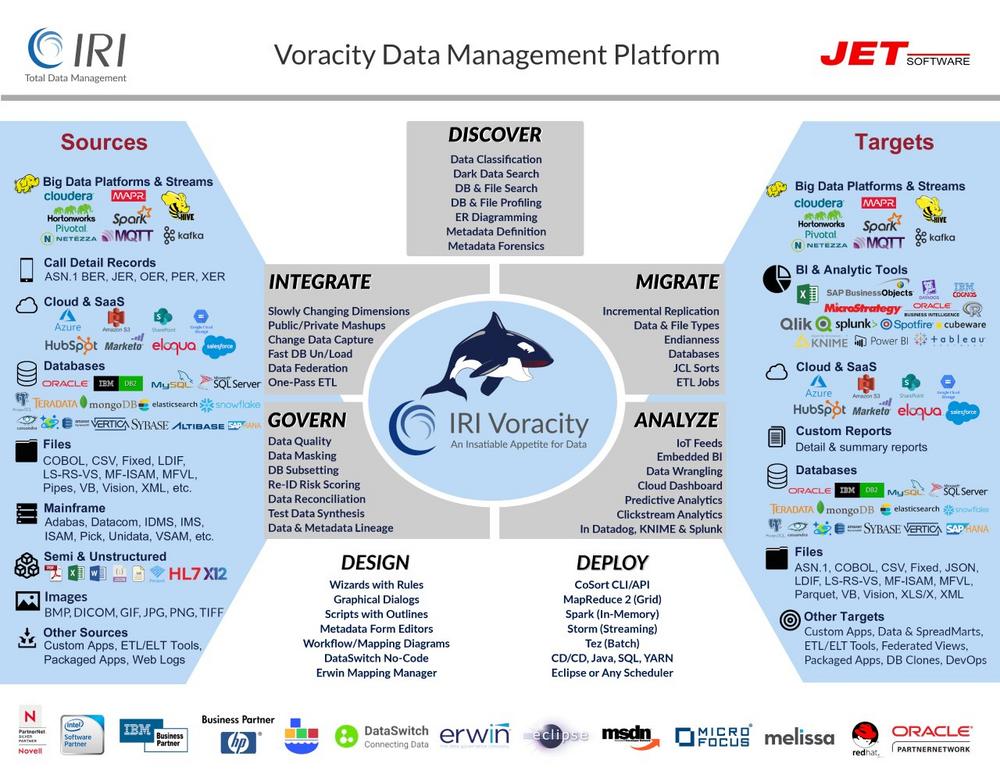
Fazit: Sie müssen den Daten genügend Vertrauen schenken, um Ihrer Analyse vertrauen zu können. Es ist also besser zu wissen und zu verwalten, was im Wasser ist. Wenn Sie IRI Voracity verwenden, können Sie Daten im See entdecken, integrieren, migrieren, verwalten und analysieren – oder testen – oder produktionsreife Ziele für andere Architekturen vorbereiten, wie ein Data Warehouse, Mart oder ODS – alles innerhalb einer verwalteten Metadaten-Infrastruktur!
Sie wollen auch in der Lage sein, den Data Lake durch verschiedene Datenbereinigungsoperationen zu säubern, zumindest so weit, wie Sie es können. Sie können Voracity nutzen, um die Datenqualität im Data Lake auf folgende Weise zu verbessern:
Finden – Entdecken, Profilieren und Klassifizieren von Daten unter Qualitätsgesichtspunkten
Filtern – Entfernen oder Speichern von bedingt ausgewählten oder doppelten Elementen
Vereinheitlichen – Daten, die durch Fuzzy-Match-Algorithmen gefunden wurden und Wahrscheinlichkeiten festlegen
Ersetzen – in Mustersuchen gefundene Daten durch Literal- oder Nachschlagewerte
Validieren – Identifizierung von Nullwerten und anderen Datenformaten durch Funktionen
Regulieren – Anwendung von Regeln, um Daten außerhalb des Bereichs oder des Kontexts zu finden und zu korrigieren
Synthetisieren – benutzerdefinierte zusammengesetzte Datentypen und neue Zeilen- oder Dateiformate
Standardisieren – Feldfunktions-APIs für Melissa Data oder Trillium verwenden
Wenn weniger Müll im See ist, wird auch weniger Müll in Ihren Analyseergebnissen auftauchen, und das Wasser wird auch für alle anderen sauberer sein.
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
Das Unternehmen JET-Software GmbH wurde 1986 in Deutschland gegründet. Seit fast 4 Jahrzehnten entwickeln wir Software für Big Data Management und Schutz! Unsere Produkte sind für alle gängigen Betriebssysteme: Mainframe (BS2000/OSD, z/OS + z/VSE) und Open Systems (UNIX & Derivate, Linux + Windows).
Wir bieten Lösungen für schnellstes Datenmanagement (Datenprofilierung, Bereinigung, Integration, Migration und Reporting sowie Beschleunigung der BI/DB/ETL-Plattform von Drittanbietern) und datenzentrierten Schutz (PII/PHI-Klassifizierung, -Erkennung und -Deidentifizierung, sowie Re-ID-Risikobewertung und Generierung synthetischer Testdaten).
Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: +49 (6073) 711403
Fax: +49 (6073) 711405
E-Mail: amadeus.thomas@jet-software.com
![]()